Zero-ETL Warehouse for Startups
Automatically sync and query data from any source. Cut months of data engineering work.
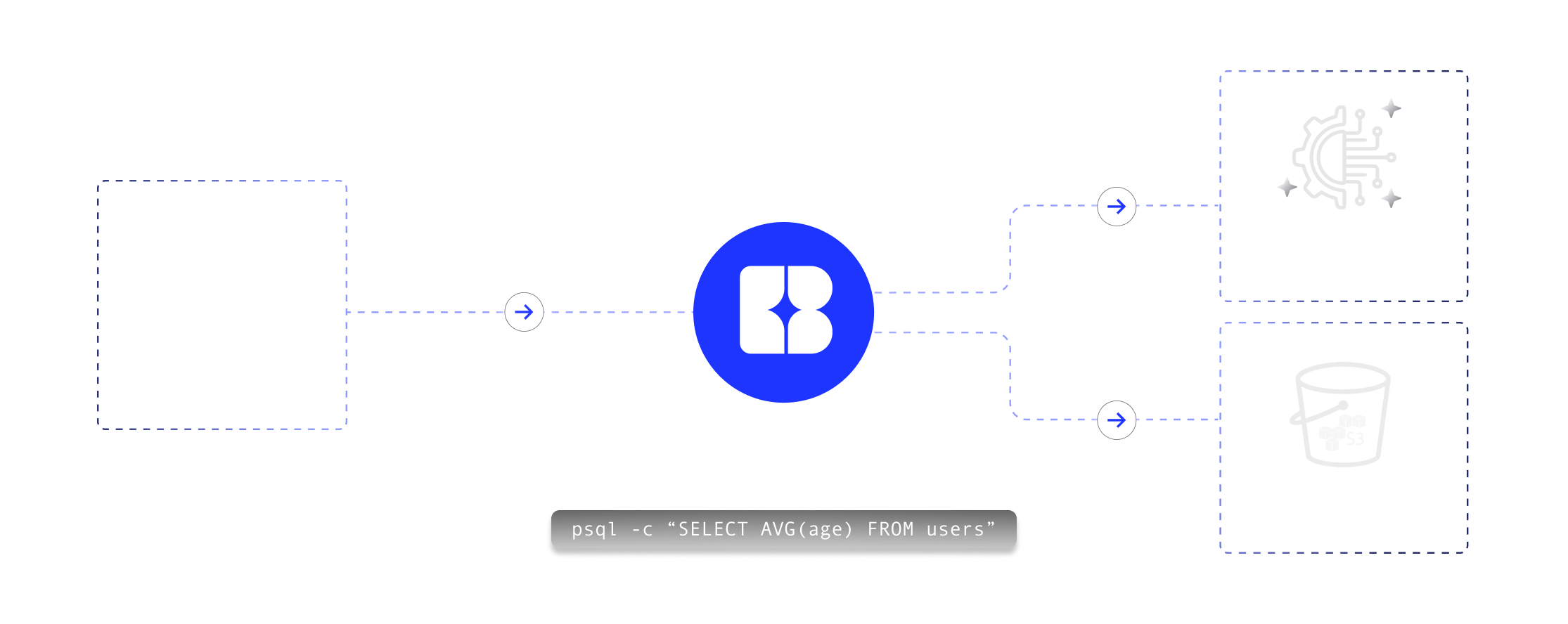
Use cases
Powerful analytics
Centralized data store
BI and ad-hoc queries
Postgres in-app analytics
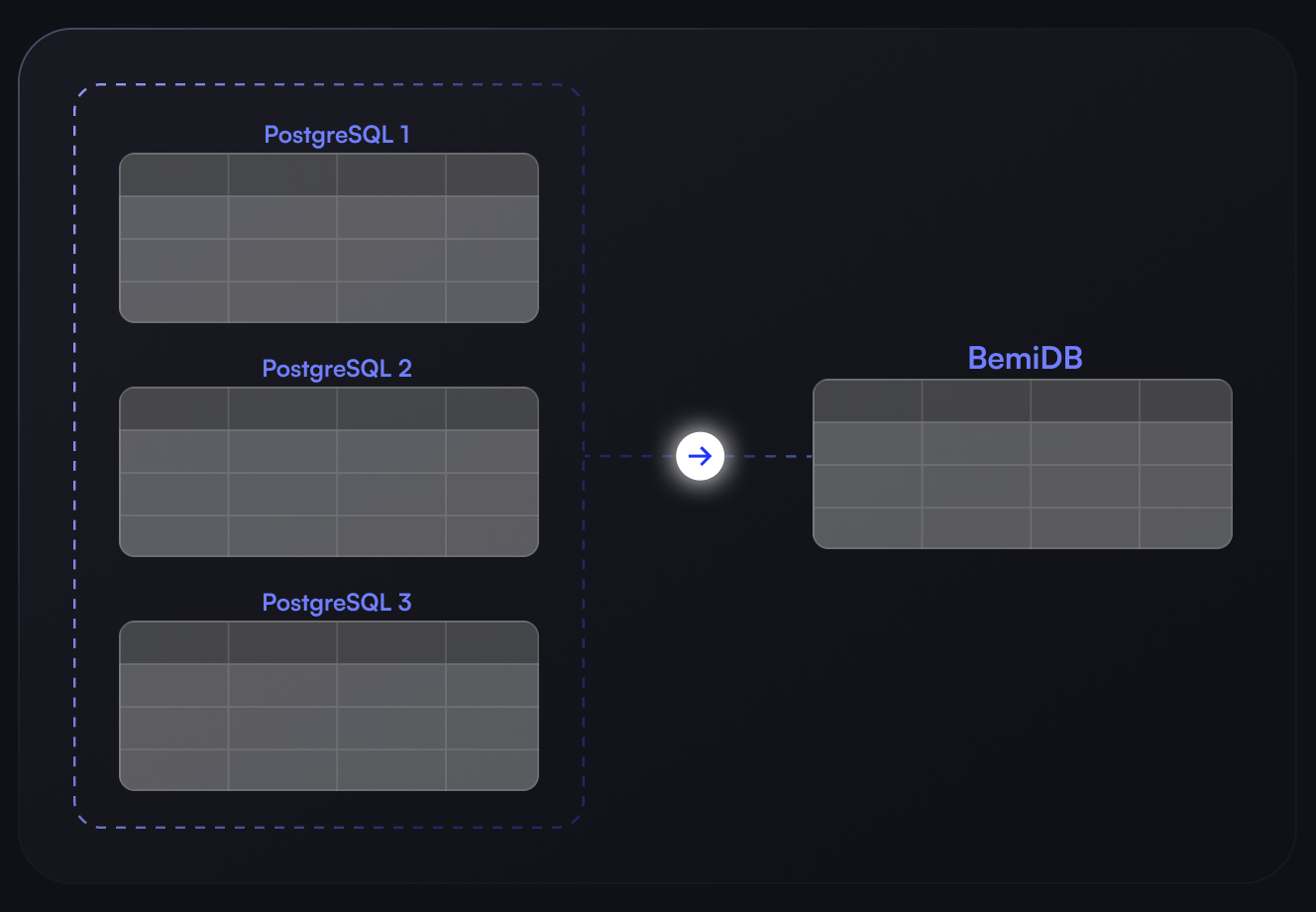
Centralize data without pipelines
Combine data from multiple sources into one unified store. Simplify your analytics and reporting with a consolidated and unlimited dataset.
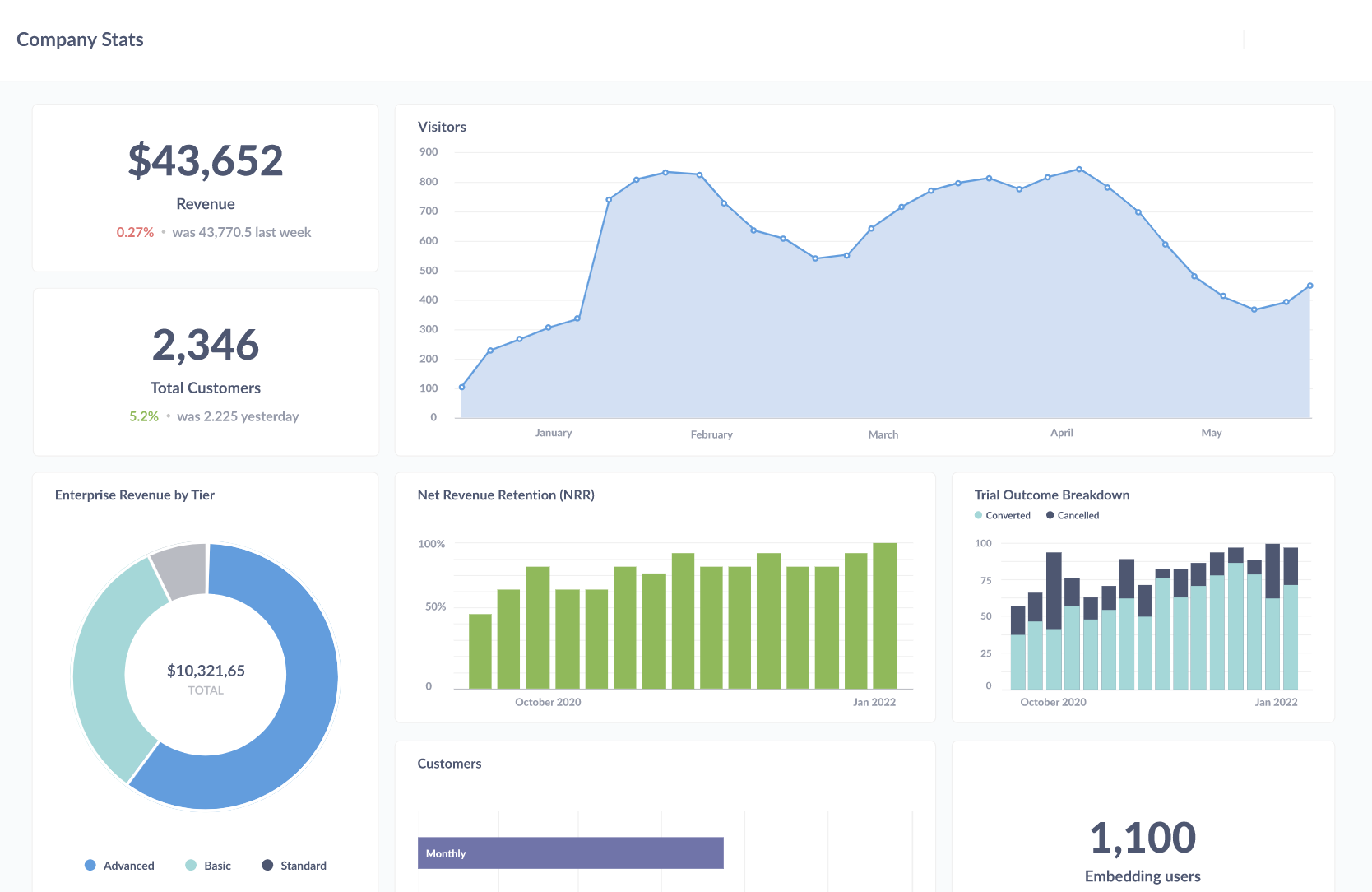
Uncover insights with ease
Build dashboards, run reports, and analyze data by connecting any Business Intelligence tools or running ad-hoc queries. Stop worrying about performance.
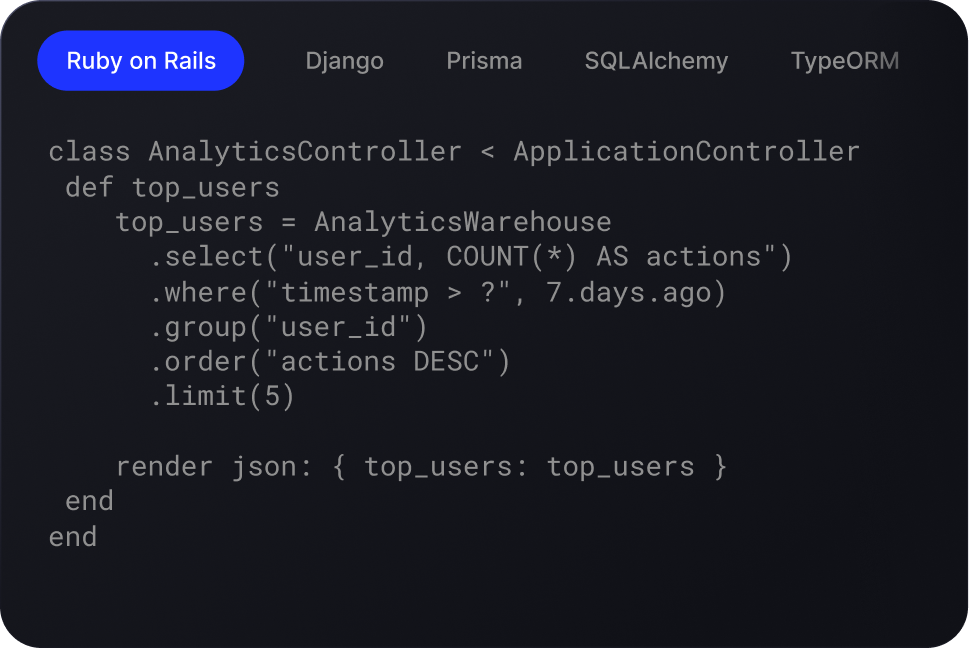
Leverage Postgres without reverse ETL
Query your analytics data directly in your application. Seamless integration with your existing database libraries. No extra adapters or proprietary layers needed.
Testimonials
Join the community
One of the fastest-growing open source data analytics projects



FAQ
Have any questions?
See BemiDB in action today
No credit card required








Blog
Discover featured posts
Engineering
Data Analytics with PostgreSQL: The Ultimate Guide
We'll compare the main approaches for running data analytics with PostgreSQL...

Engineering
When Postgres Indexing Went Wrong
Understand the basics of how indexing really works and the best practices for preventing system downtime...

Engineering
It’s Time to Rethink Event Sourcing
The traditional approach to implementing Event Sourcing comes with many challenges. We'll explore new ideas...